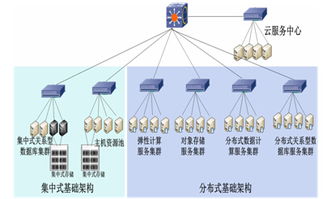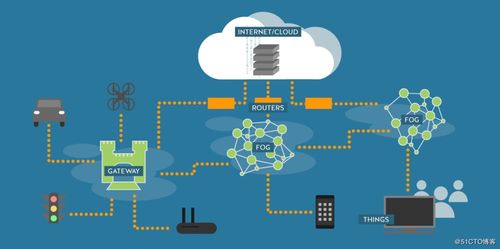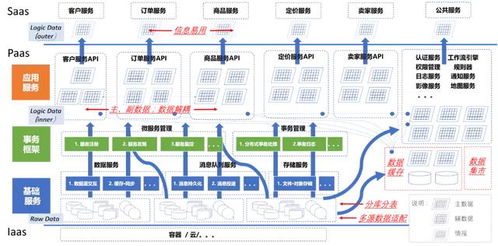
隨著大數據時代的到來,數據工程已成為支撐現代企業數字化轉型的核心支柱。本指南旨在系統性地介紹數據工程的關鍵組成部分,特別是數據處理與存儲服務的架構設計、技術選型與最佳實踐,幫助讀者構建高效、可擴展且可靠的數據基礎設施。
一、數據工程的基石:理解數據處理與存儲
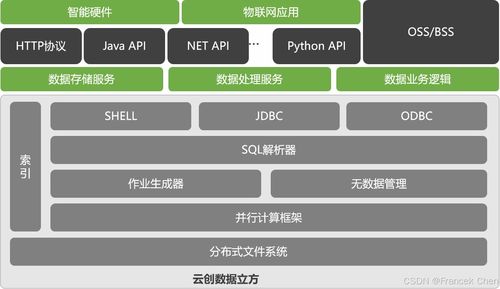
數據工程的核心任務是將原始數據轉化為可供分析和應用的可靠信息資產。這涉及兩個關鍵環節:數據處理與數據存儲。數據處理負責數據的清洗、轉換、集成與計算;數據存儲則為處理前、中、后的數據提供持久化、組織化的存放空間。兩者緊密協作,共同構成數據管道的“心臟”與“倉庫”。
二、數據處理服務:從批處理到實時流
現代數據處理服務已從傳統的批量ETL(提取、轉換、加載)演化為涵蓋流處理的混合架構。
- 批處理服務:適用于對時效性要求不高的大規模歷史數據分析。常用技術包括:
- Apache Hadoop MapReduce:經典的分布式計算框架。
- Apache Spark:憑借內存計算和豐富的API(如Spark SQL、DataFrame),成為批處理的主流選擇,尤其擅長迭代計算和復雜ETL。
- 云原生服務:如AWS Glue、Azure Data Factory、Google Cloud Dataflow,提供全托管的ETL編排與執行環境。
- 流處理服務:用于處理連續不斷的數據流,實現近實時或實時的洞察與響應。關鍵技術包括:
- Apache Kafka Streams / KsqlDB:與Kafka深度集成,用于構建流式應用和實時查詢。
- Apache Flink:提供高吞吐、低延遲、Exactly-Once語義的流處理能力,同時支持批流一體。
- Apache Storm / Samza:早期的流處理框架,仍在特定場景下使用。
- 云服務:如AWS Kinesis Data Analytics、Google Cloud Dataflow(流模式)、Azure Stream Analytics。
- 處理范式演進:
- Lambda架構:結合批處理層(處理全量數據,保證準確性)和速度層(處理實時數據,保證低延遲),通過服務層合并視圖。復雜度較高。
- Kappa架構:簡化架構,主張所有數據都通過流處理系統處理,歷史數據通過重播數據流來重新計算。對流的可靠性和計算能力要求高。
- 數據湖倉一體(Lakehouse):如Delta Lake、Apache Iceberg、Hudi,在數據湖(低成本存儲)之上引入事務、模式管理等數據倉庫特性,簡化了批流統一處理和數據管理。
三、數據存儲服務:分層存儲與格式選擇
選擇合適的數據存儲服務取決于數據的結構、訪問模式、規模與成本。
- 在線事務處理(OLTP)數據庫:
- 關系型數據庫(RDBMS):如PostgreSQL、MySQL、云RDS服務。適用于強一致性、事務性操作的結構化數據。
- NoSQL數據庫:
- 鍵值存儲:如Redis(內存)、DynamoDB。用于高速緩存與會話存儲。
- 文檔數據庫:如MongoDB、Couchbase。存儲半結構化文檔,模式靈活。
- 寬列存儲:如Cassandra、HBase、Bigtable。適合時間序列、大規模稀疏數據。
- 圖數據庫:如Neo4j、Amazon Neptune。高效處理實體間復雜關系。
- 數據倉庫(OLAP):
- 專為復雜分析和快速聚合查詢優化。如Snowflake、Google BigQuery、Amazon Redshift、Azure Synapse Analytics。它們通常采用列式存儲和分離計算與存儲的架構,實現高性能分析。
- 數據湖存儲:
- 用于集中存儲任意規模的結構化、半結構化和非結構化原始數據。核心是低成本、高可擴展的對象存儲服務,如AWS S3、Azure Blob Storage、Google Cloud Storage。數據湖是構建Lakehouse的基礎。
- 文件格式與存儲優化:
- 列式存儲格式:如Parquet、ORC,極大提升分析查詢性能,因其只讀取所需列并支持高效壓縮。
- 存儲分層:根據訪問頻率將數據分為熱(高頻訪問,高性能存儲)、溫、冷(歸檔,低成本存儲)層,以優化成本效益。
四、構建健壯的數據處理與存儲架構:最佳實踐
- 設計可擴展的管道:采用微服務或Serverless架構,利用云服務的自動擴縮容能力應對負載變化。
- 確保數據質量與可靠性:在管道中嵌入數據驗證、監控和告警。實現數據血緣追蹤和元數據管理。處理服務應支持容錯和Exactly-Once或At-Least-Once語義。
- 安全與治理:實施端到端的數據加密(傳輸中與靜態)、細粒度的訪問控制(IAM、RBAC)、數據脫敏與合規性檢查。
- 成本優化:選擇與工作負載匹配的存儲類型和計算資源。利用自動壓縮、數據生命周期策略、預留實例等手段控制成本。
- 擁抱現代化架構:評估Lakehouse架構,它通過開放格式(Parquet/ORC)和表格式(Delta/Iceberg/Hudi)的統一,簡化了批流處理和數據管理,正成為新趨勢。
五、與展望
數據處理與存儲服務是數據工程的血肉與骨架。成功的實施需要深入理解業務需求,并明智地選擇和組合批處理與流處理技術,同時為不同類型的數據匹配合適的存儲方案。隨著云原生、AI集成和實時化需求的增長,Serverless數據處理、智能分層存儲以及更強大的實時湖倉能力將繼續推動該領域快速演進。持續關注開源生態與云服務商的新進展,是保持數據平臺競爭力的關鍵。